
La inteligencia artificial (IA) es un subcampo de la informática que se centra en el desarrollo de algoritmos, sistemas y técnicas que permiten a las máquinas y programas de software aprender, razonar, planificar, percibir, comunicarse y resolver problemas de manera similar a como lo hacen los seres humanos. El objetivo principal de la IA es crear sistemas que puedan realizar tareas que normalmente requieren inteligencia humana.
Reseña histórica del avance de la Inteligencia artificial
El concepto moderno de IA comenzó a tomar forma en el siglo XX, con avances en matemáticas, lógica y computación. En 1931 Kurt Gödel demostró que hay límites en lo que puede ser demostrado o refutado dentro de un sistema formal, lo que influyó en la teoría de la computación y la lógica en el desarrollo de la IA. Años mas tarde, entre 1940 y 1960, tuvo lugar la cibernética, liderada por Norbert Wiener; fue un movimiento interdisciplinario que estudió la regulación y control en sistemas biológicos y artificiales, y sus ideas influyeron en la forma en que se abordaron problemas en IA, particularmente en la percepción y control de agentes autónomos.
Durante la década de 1940 y 1950, trabajos en lógica matemática y teoría de la computación por Claude Shannon, Kurt Gödel y otros sentaron las bases para representar y manipular el conocimiento en sistemas informáticos.
En los 50s el matemático británico Alan Turing propuso la Máquina de Turing, un modelo teórico de cómputo que sienta las bases para la informática moderna. Turing también planteó la pregunta “¿Pueden pensar las máquinas?” en su artículo de 1950 “Computing Machinery and Intelligence”, donde introdujo el Test de Turing para evaluar si una máquina puede imitar la inteligencia humana.

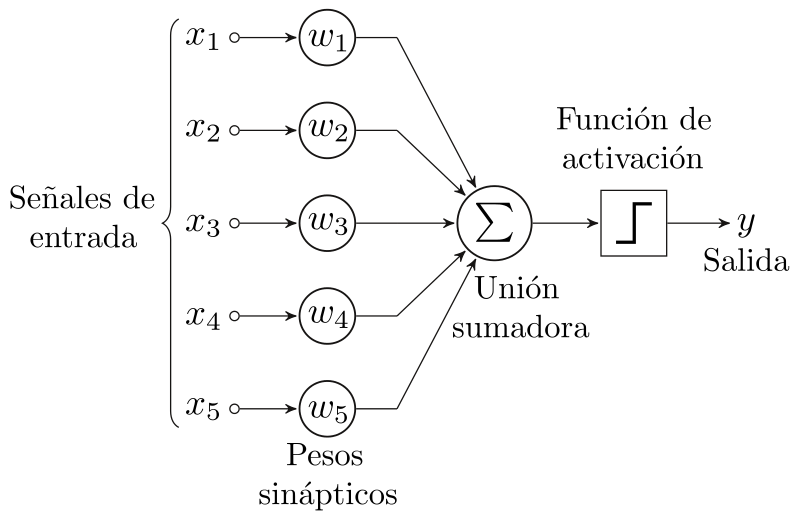
En 1958 Frank Rosenblatt desarrolló el perceptrón, un algoritmo de aprendizaje supervisado simple para el entrenamiento de redes neuronales artificiales de una sola capa. A pesar de sus limitaciones, el perceptrón influyó en el desarrollo de algoritmos de aprendizaje automático y redes neuronales.
La conferencia de Dartmouth (1956), organizada por John McCarthy, Marvin Minsky, Nathaniel Rochester y Claude Shannon, es considerada el evento fundacional de la inteligencia artificial como campo de estudio. Durante esta conferencia, los investigadores discutieron y definieron los objetivos y enfoques de la IA. Aunque no se estableció una lista concreta y detallada de objetivos en la propuesta original, la conferencia abordó varias áreas y enfoques que moldearían el campo de la IA en los años venideros:
- Simulación del aprendizaje: Los investigadores propusieron estudiar cómo las máquinas podrían aprender y mejorar su rendimiento en diversas tareas, similar al proceso de aprendizaje humano.
- Representación del conocimiento: Se discutió la necesidad de desarrollar sistemas capaces de representar y almacenar información, así como métodos para razonar sobre dicha información para resolver problemas.
- Razonamiento basado en reglas: Los participantes exploraron el desarrollo de sistemas que podrían razonar y tomar decisiones utilizando reglas lógicas y heurísticas, lo que eventualmente condujo a la creación de sistemas expertos.
- Simulación del lenguaje natural: Se propuso investigar cómo las máquinas podrían comprender y procesar el lenguaje humano, lo que condujo al desarrollo de la rama del procesamiento del lenguaje natural (NLP) en la IA.
- Reducción de problemas y búsqueda: La conferencia también abordó enfoques para la descomposición de problemas en subproblemas y la búsqueda de soluciones a través de algoritmos y heurísticas.
- Automatización de habilidades perceptivas y motoras: Los investigadores discutieron la posibilidad de enseñar a las máquinas a percibir el entorno y realizar tareas físicas, sentando las bases para el desarrollo de la visión por computadora y la robótica.
- Auto-mejora: Se planteó la idea de que las máquinas deberían ser capaces de mejorar su propio rendimiento y adaptarse a nuevas situaciones a lo largo del tiempo, un concepto que es fundamental en el aprendizaje automático y la inteligencia artificial en general.
En 1959 Allen Newell y Herbert A. Simón desarrollaron el “General Problem Solver” (GPS), uno de los primeros programas de inteligencia artificial diseñados para imitar el razonamiento humano en la resolución de problemas. GPS utilizó búsqueda en el espacio del problema y reglas heurísticas para encontrar soluciones.
Entre 1960 y 1980 se crearon sistemas basados en conocimientos y reglas, como DENDRAL y MYCIN, que podían razonar en dominios específicos y tomar decisiones basadas en información almacenada.
En 1964 Joseph Weizenbaum creó ELIZA, un programa de computadora que simulaba un terapeuta Rogeriano. Aunque su capacidad de comprensión era limitada, ELIZA demostró que las máquinas podían generar respuestas que parecían inteligentes, lo que influyó en el desarrollo de chatbots y sistemas de diálogo.
En 1965 Lotfi Zadeh desarrolló la teoría de conjuntos difusos y la lógica difusa, que permiten modelar la incertidumbre y la vaguedad en el razonamiento humano. La lógica difusa ha encontrado aplicaciones en sistemas de control, toma de decisiones y procesamiento del lenguaje natural.
En 1969 Marvin Minsky y Seymour Papert publicaron “Perceptrons”, un libro que analizaba las limitaciones de las redes neuronales de una sola capa y destacaba la necesidad de modelos más complejos. Este trabajo tuvo un efecto inhibidor en la investigación de redes neuronales durante un tiempo, pero también sentó las bases para el futuro desarrollo de redes neuronales más avanzadas.
En 1970 John Holland desarrolló algoritmos genéticos, un enfoque de optimización basado en la evolución natural. Los algoritmos genéticos se utilizan en la búsqueda y optimización de soluciones en una amplia gama de problemas de IA.
A partir de la década de 1980, los enfoques basados en aprendizaje automático comenzaron a ganar popularidad, con algoritmos como las redes neuronales, algoritmos genéticos y máquinas de soporte vectorial. Estos enfoques permiten a las máquinas aprender a partir de datos en lugar de depender de reglas predefinidas.
Geoffrey Hinton, David Rumelhart y Ronald Williams en 1986 publicaron un artículo que presentaba el algoritmo de retropropagación, un método eficiente para entrenar redes neuronales de múltiples capas. Este avance revitalizó la investigación en redes neuronales y sentó las bases para el desarrollo posterior del aprendizaje profundo.
Vapnik y Chervonenkis en 1990 presentaron las máquinas de soporte vectorial (SVM), un enfoque de aprendizaje automático supervisado que utiliza técnicas de optimización para clasificar datos en dos o más clases. Las SVM se convirtieron en uno de los principales métodos en aprendizaje automático antes de la popularización del aprendizaje profundo.
En 1997 nace Deep Blue, un supercomputador desarrollado por IBM que derrotó al campeón mundial de ajedrez Garry Kasparov en un match histórico. Este evento demostró el potencial de la inteligencia artificial en la resolución de problemas complejos y captó la atención del público.

Con la creciente popularidad de Internet y el comercio electrónico, se desarrollaron sistemas de recomendación basados en IA para ayudar a los usuarios a encontrar contenido relevante y productos, como el filtrado colaborativo utilizado por Amazon y el algoritmo de PageRank de Google, esta tecnología se desarrolló enntre 1990 y el 2000.
La investigación en robótica y vehículos autónomos inicia desde el año 2000 y ha avanzado significativamente en las últimas décadas, con proyectos como el desafío DARPA Grand Challenge y empresas como Waymo, Tesla y otras desarrollando vehículos autónomos que utilizan técnicas de IA para la percepción, planificación y control.

El aprendizaje profundo fue abordado desde el 2006, como un subcampo del aprendizaje automático, y el que ha experimentado un rápido crecimiento en la última década, gracias a avances en la disponibilidad de datos, potencia de cómputo y algoritmos. Las redes neuronales profundas han demostrado ser extremadamente efectivas en tareas como reconocimiento de imágenes, traducción automática y generación de texto.
A partir del 2010 se desarrollaron los asistentes virtuales como Apple Siri, Amazon Alexa y Google Assistant, los mismos que utilizan procesamiento del lenguaje natural y aprendizaje automático para comprender y responder a las consultas de los usuarios.
Desarrollados por DeepMind (adquirida por Google), AlphaGo y AlphaZero (2016-2017) utilizaron técnicas de aprendizaje profundo y aprendizaje por refuerzo para dominar los juegos de Go y ajedrez, respectivamente. Estos sistemas demostraron avances significativos en la capacidad de las máquinas para aprender y optimizar estrategias en problemas altamente complejos.
En el 2023 OpenAI presentó la tercera generación de su modelo de lenguaje generativo Transformer, GPT-3, que es capaz de realizar una amplia variedad de tareas de procesamiento del lenguaje natural con alta calidad. GPT-3 ha sido considerado un hito en la investigación de IA debido a su versatilidad y capacidad de generar texto humanoide.
